Current projects
Research Projects
Projects supported by industry partners
Semantics and Implementation of ACID properties in modern hardware [Gustavo Alonso]
SoftHier: Exploring Explicitly Managed Memory Hierarchy Architectures for Scalable Acceleration [Torsten Hoefler/Luca Benini]
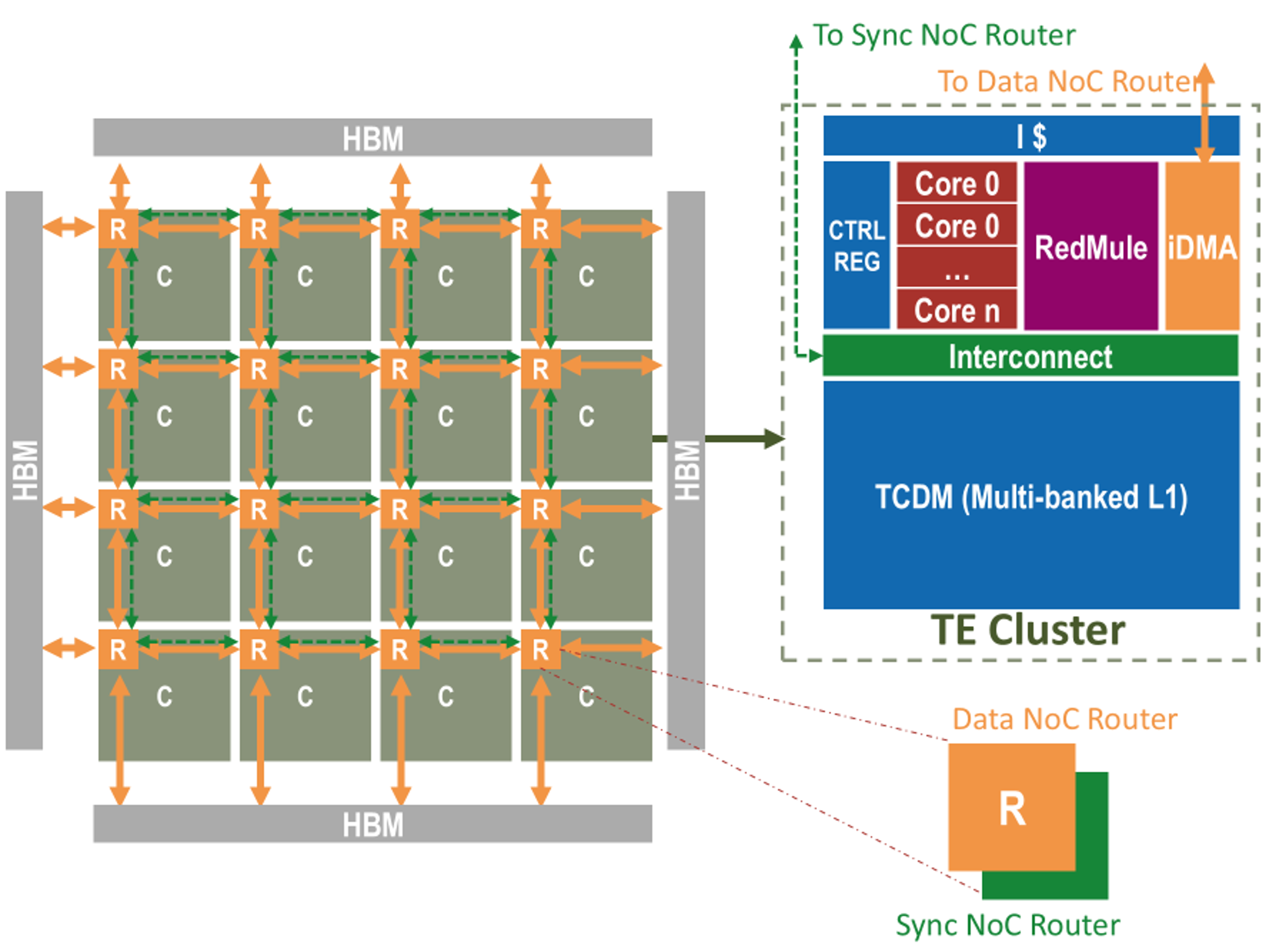
The objective of SoftHier is to drastically reduce hardware inefficiency by replac-ing caches with software-managed, efficient SPMs and DMAs, while maintaining program-ming effort low for the application developer. This goal will be achieved thanks to: (i) An increased level of automation in the programming tool-flow; (ii) The use of domain-specific languages and abstractions; (iii) Hardware enhancements in the memory hierarchy that facilitate automatic instantiation of accelerated data-motion primitives from abstract, streamlined software APIs.
Key achievements:
- Defined baseline template architecture for SoftHier, explored GEMM dataflow mapping, architecture design space, PPA
- Developed a High-Level Simulation Model with Open-source release
- PPA estimation for SoftHier Architecture
QuantSparse3D: A Stacked-Memory Multi-Chiplet inference Engine for Sparse, Quantized LLMs [Luca Benini]

The QuantSparse3D project aims to mitigate the energy bottleneck (i.e. scaling performance under power constraints) of LLM, and more generally FM, inference workloads.
Three main co-design ideas are pursued to achieve the goal.
First, we will leverage sparsity and quantization for reducing computations, memory footprint and bandwidth, by providing architectural support for sparse and quantized computations across the hierarchy (from L0 - registers to L3 - Main memory). Second, we will enable the dynamic distribution of sparse and quantized computation across the memory hierarchy, depending on the computational intensity. Third, we will exploit the emerging three-dimensional heterogeneous (logic, volatile and non-volatile memory) integration technology options from 2.5D – chiplets, to 3D – stacked ICs with hybrid bonding, to minimize the energy overhead in data movement.
LLM Agent Firewall [Srdjan Capkun]

Large Language Model (LLM) agents offer increasingly rich functionalities and capabilities to act on users' inputs and data. However, it remains unclear how to safely restrict LLM agents to the desired data and functionalities, and what are their implications on the privacy and integrity of the systems that they operate in.
In this project, we investigate how LLM agents need to be restricted in terms of the access to system data and resources, actions that they are allowed to take, and which access control models and mechanisms should be deployed to achieve access control and isolation properties. It is not yet clear whether existing solutions can be leveraged in an agentic setting and what are the tradeoffs of different solutions. For example, in a corporate setting where different roles have access to different projects, a single assistant trained on all the company's data provides efficient training but insufficient access control due to threats such as memorization and membership inference attacks. Instead, training one model for each permission level can quickly lead to training an exponential number of models.
We aim to analyze the combinations of novel LLM environments that will restrict the agents, novel system access control policies and LLM training, all of which combined will limit LLM agents. This is a challenging problem, as solutions must (i) guarantee information isolation between different groups while (ii) allowing computationally reasonable training, finetuning, and updating, and (iii) not harming functionality and providing high-quality results.
Graph Computations and LLMs: A Synergy [Torsten Hoefler]
In this project, we will explore the synergy between graph computing and LLMs in order to improve the efficiency and effectiveness of both classes of workloads.On one hand, we will work on enhancing the LLM ecosystem by exploring – for example – how to harness the graph abstraction for more powerful LLM inference and agent architectures, how to enhance the design of Retrieval Augmented Generation (RAG), or how to extend the fine tuning pipeline of LLMs with graph tasks for more powerful LLM reasoning. Here, we will build upon - among others - our recent LLM outcomes such as Graph of Thoughts or Topologies of Reasoning. One example approach is the integration of Retrieval-Augmented Generation (RAG), which allows models to offload part of the memory burden by retrieving relevant external information dynamically. However, RAG alone may not address the full scope of long-term memory needs, especially when managing long-term dependencies or multitasking over extended contexts.
Similarly, we will explore the potential of harnessing graphs for more effective Transformers. Transformers have demonstrated remarkable success in various tasks, but one area that remains under-explored is the integration of graph structures to enhance their capacity and efficiency. A promising avenue is reorganizing Mixture of Experts (MOEs) using a graph-based structure. Instead of treating experts as independent units that are selectively activated, a graph topology can be employed, where each expert becomes a node, and the edges represent pathways of knowledge transfer or communication between experts. Finally, fine-tuning LLMs on graph-based tasks presents a unique opportunity to enhance the model's performance on graph tasks such as node classification or link prediction. If time allows, we will also explore this direction.
Unifying High-Performance Automated Differentiation for Machine Learning and Scientific Computing [Torsten Hoefler]

In this project, we aim to develop a high-performance automatic differentiation framework capable of supporting both machine learning models (from PyTorch/ONNX) and complex scientific computing programs (Python, Fortran, etc.). This will bridge the gap between the two fields and enable the exploration of hybrid learning techniques that outperform classical scientific approaches. To enable the differentiation of larger, memory-intensive programs, we will explore novel techniques for automatic checkpointing. We leverage the power of the stateful data-flow graph (SDFG) representation, on which we apply AD, statically analyze the graph to determine which activations to recompute or store, and utilize data-centric optimizations to enhance the gradient calculation performance.
Key Achievements:
- State-of-the-art performance for gradient calculation on NPBench kernels outperforming JAX
- ILP-Based solution for the store-recompute problem in automatic differentiation
Processing-in-Memory Architectures for Data-Intensive Applications [Onur Mutlu]
Data movement between the memory units and the compute units of current computing systems is a major performance and energy bottleneck. From large-scale servers to mobile devices, data movement costs dominate computation costs in terms of both performance and energy consumption. For example, data movement between the main memory and the processing cores accounts for 62% of the total system energy in popular consumer applications run on mobile systems, including web browsing, video processing, and machine learning (ML) inference, as we analyzed and demonstrated in our ASPLOS 2018 paper. Our more recent study in PACT 2021 shows that more than 90% of the total system energy is spent on memory in large edge ML models. As a result, the data movement bottleneck is a huge burden that greatly limits the efficiency and performance of modern computing systems.
Many modern and important workloads such as ML models (including large language models (LLMs)), graph processing, rendering, databases, video analytics, real-time data analytics, and computational biology suffer greatly from the data movement bottleneck. These workloads are exemplified by irregular memory accesses, relatively low data reuse, low cache utilization, low arithmetic intensity (i.e., ratio of operations per accessed byte), and large datasets that greatly exceed the main memory size. The amounts of computation and locality present in these workloads cannot usually amortize the data movement costs. In order to alleviate this data movement bottleneck, we need a paradigm shift from the traditional processor-centric design, where all computation takes place in the compute units in the processor, to a more data-centric design, where processing elements are placed closer to where the data resides. This paradigm of computing is known as Near-Data Processing (NDP) or Processing-in-Memory (PIM). PIM architectures can be classified into two categories: 1) Processing-near-Memory (PnM), where computation takes place in dedicated processing elements (e.g., accelerators, processing cores, reconfigurable logic) placed near the memory array, and 2) Processing-using-Memory (PuM), where computation takes place inside the memory array by exploiting intrinsic analog operational properties of the memory device.
In this project, we aim to fundamentally alleviate data movement bottleneck and, thus, significantly accelerate modern data-intensive applications, such as large-scale ML models, LLMs, graph processing, rendering, databases, video analytics, real-time data analytics, and computational biology using PIM architectures
Research Grants
Internal research projects supported by an EFCL grant
Revolutionizing Assisted Living with Robotic Dogs: Embedding AI-Based On-Board Processing and Novel Sensors [Michele Magno]

Assistive robotics opens new possibilities to support people with visual impairments, enhancing their independence and safety in daily life. This project explores the use of small, agile quadrupedal robots as intelligent mobility aids capable of operating in complex indoor environments.
Traditional aids such as white canes and guide dogs have been used for decades but have inherent limitations: a cane can only detect nearby obstacles, and guide dogs, although highly capable, are costly and not widely available. This project aims to bridge that gap by developing robotic guide dogs that combine autonomous navigation, reliable mobility, and intuitive interaction. The system performs all perception, mapping, and decision-making entirely on board, operating independently of external infrastructure. It combines depth and environmental sensing, voice-based human-robot interaction, and collision avoidance, and has already demonstrated safe multi-floor navigation in real-world tests with visually impaired users.
By combining robust locomotion, embedded intelligence, and accessible design, the project advances toward practical robotic assistants that can enhance safe and independent mobility for visually impaired people.
Key achievements:
- Developed a functional robotic guide dog prototype, with a custom-designed embedded system, featuring robust collision avoidance, voice-based human-robot interaction, and safe multi-floor navigation, integrated with HifrETH ETH’s PolyMaps service.
- Conducted the first successful experiments of the developed autonomous robot with visually impaired users, receiving positive initial feedback on guidance performance and usability.
- Achieved state-of-the-art quadruped locomotion control, enabling stair-climbing and rough-terrain traversal, with system performance validated through extensive real-world trials and recognized by winning the ICRA 2025 Quadruped Robot Challenge
Contact
Michele MagnoFoundation Models for Biosignal Analysis [Luca Benini]

This project develops a new generation of artificial intelligence models for analyzing biological signals such as brain activity (EEG), heart signals (ECG), and blood flow signals (PPG), muscle signals (EMG). These signals are widely used in healthcare, for example in monitoring neurological disorders, detecting heart conditions, or enabling brain-computer interfaces.
Current AI systems are typically designed for a single type of signal and struggle to generalize across different sensors, hospitals, or patient populations. Our project addresses this limitation by building foundation models that can learn from different types of biosignals. This model can adapt to different sensor configurations and operate efficiently even on long recordings.
To achieve this, we combine three key innovations: (1) a method to standardize heterogeneous sensor layouts, (2) efficient architectures that scale to large datasets, and (3) adaptive computation mechanisms that adjust processing effort based on signal complexity.
The outcome is a robust and efficient AI system that improves diagnostic accuracy, reduces the need for labeled data, and enables deployment on resource-constrained devices such as wearable monitors. This contributes to more scalable and accessible healthcare technologies.
Key achievements:
- Developed a multi-modal biosignal foundation model architecture integrating topology-agnostic input handling, efficient temporal modeling, and scalable attention mechanisms.
- Established a scalable training pipeline on HPC infrastructure, demonstrating near-linear scaling and high parallel efficiency for large-scale biosignal pre-training
- Built the BioFoundation framework, enabling reproducible, modular, and distributed training across heterogeneous biosignal datasets
Contact
Yawei LiFall Injury Classification [Torsten Hoefler]
Our objective is to decrease the rate of hospital admissions due to fall-related injuries while also minimizing the complications that arise when such injuries do occur.
The injury risk to the hip when falling can be assessed by using medical imaging techniques to build a three-dimensional model of a person’s hip, which is then used as input for finite element simulations of different fall scenarios. Such simulations are computationally expensive, and its inputs involve confidential patient data, and thus cannot be performed in the cloud.
The key to this project is to reduce the computation cost of fall-related hip injury prediction using AI methods. The most effective way to do this is not known, we will investigate multiple approaches, such as training a GNN on voxel data (which completely replaces the existing simulation pipeline) and using automatic differentiation to accelerate the existing simulation.
We will train our models using federated learning, enabling decentralized training while preserving data privacy. This approach allows collaboration without sharing sensitive data, improving model accuracy with a diverse dataset. We aim to train a large model on the server and then scale it down for use on client devices like those in hospitals, making it efficient for hardware with limited computational resources.
To summarize, our model will enable healthcare providers and individuals to take proactive steps to reduce fall-related injury risks, improving patient outcomes and lowering healthcare costs. With a privacy-focused, data-driven approach, we aim to advance fall prevention and intervention strategies.
Contact
Timo SchneiderMetagenomic Analysis on Near-Data-Processing Platforms [Onur Mutlu]
Metagenomics applications monitor the diversity of organisms in different environments and are critical in clinical practice and public health. State-of-the-art analyses rely on high throughput sequencing for microorganism identification but suffer from a huge memory footprint, frequent data movement, and high dependency on internet access. This causes intense congestion in the network, high power consumption, and raises privacy concerns. To this end, it is paramount to perform high-speed genome detection locally for screening and diagnostic purposes. General genomic accelerator designs are suboptimal for metagenomics acceleration as they are not tailored to the specific pipeline steps, they neglect end-to-end acceleration and do not consider the significantly larger amounts of data. The goal of this project is to accelerate metagenomics for small-edge devices leveraging the near-data-processing (NDP) paradigm, as it can effectively address the huge data size, massive data movement, and parallel computation requirements of metagenomics. We aim to perform a holistic study of metagenomic algorithms and exploit processing-near-memory or in-storage subsystem (PNM) and processing-using-memory (PUM) to accelerate metagenomics steps. The result will be an end-to-end NDP system that combines both PNM and PUM proposed accelerators in a co-designed approach that seamlessly integrates within a metagenomics pipeline.
Contact
Mohammad Sadrosadati4D Dynamic Tracking and Reconstruction [Prof. Siyu Tang]
Our world is inherently dynamic, continuously changing and evolving over time. For intelligent systems to operate successfully in such environments, they must go beyond understanding static scenes and instead perceive how the world changes over time. This requires capturing not only the 3D structure of environments but also the full 4D dynamics: how geometry, motion, and interactions develop across time. Achieving this understanding involves accurately modeling temporal relationships, tracking how elements move and transform, and reconstructing coherent representations of dynamic scenes from visual observations.
This project aims to develop a general-purpose foundation model for dynamic 4D reconstruction. Rather than focusing solely on tracking points or objects, our goal is to reconstruct complete, temporally consistent representations of dynamic scenes from multiview videos. The system will identify temporal correspondences, model motion, and recover the structure of complex, real-world environments as they evolve. Designed to be domainagnostic, it will generalize across diverse application scenarios and camera setups.
Contact
Siyu TangRethinking network router design with co-packaged optics [Prof. L. Vanbever]

Optical communication has long been used in wired networking, but primarily to interconnect network routers. Traditionally, there has been a clear separation between the optical and electrical domains, currently realized by standardized pluggable transceivers.
In recent years, we have seen the development and arrival on the market of new types of optical hardware: co-packaged optical switches and silicon photonics. These allow bringing the optical to electrical conversion very close to the switching ASIC, inside the router. Thus, it opens new potential for performing some of the router’s functionality in the optical domain—or even rethink the entire router design based on optical processing.
This project aims to explore the potential performance gains in bandwidth and energy efficiency enabled by integrating this new optical technology within network routers.
Contact
Romain JacobStudent projects
Smaller projects based on pre-PhD research supported by an EFCL grant
Integrating a PULP SoC as a CubeSat Test Article [Luca Benini]
CubeSats, tiny, cost-effective satellites, have opened up new possibilities for exploring space, making it easier for researchers and educators to launch their projects beyond Earth. However, these miniature satellites face tough challenges in space, such as harmful radiation and extreme temperatures, which can damage their electronic parts and affect their performance.
The Trikarenos System on Chip (SoC) is a research prototype system designed with standard technologies to operate in environments affected by radiation. It includes smart features that help it correct errors caused by radiation, ensuring it remains reliable and keeps functioning correctly.
The project's main goal is to test Trikeranos by integrating it into a CubeSat mission called ARIS SAGE. This test will show how well the Trikarenos SoC works when affected by radiations and will help improve how CubeSats operate in future missions.
This effort aligns with the interests of the ETH Future Computing Laboratory in making computing devices more reliable. By successfully completing this project, we hope to gain valuable insights that could help in designing future technology that can perform well in extreme conditions, both in space and on Earth.
Key achievements:
- ARIS with EFCL support developed a CubeSat On-Board Computer (OBC) platform and integrated a small test board with Trikarenos as a payload.
- This OBC with Trikarenos was integrated with a separate satellite platform to be flown as an initial test.
- This test board, along with Trikarenos, was launched within another satellite platform on a SpaceX Transporter mission on March 14, 2025.
Contact
Michael RogenmoserRevisiting Memory Performance Attacks in the Era of RowHammer Defenses [Onur Mutlu]
RowHammer is a major DRAM read disturbance mechanism, where repeatedly accessing (hammering) a row of DRAM cells (DRAM row) induces bitflips in other physically nearby DRAM rows. RowHammer solutions perform preventive actions (e.g., refresh neighbor rows of the hammered row) that mitigate such bitflips to preserve memory isolation, a fundamental building block of security and privacy in modern computing systems. However, preventive actions induce non-negligible memory request latency and system performance overheads as they interfere with memory requests. As shrinking technology node size over DRAM chip generations exacerbates RowHammer, the overheads of RowHammer solutions become prohibitively expensive. As a result, a malicious program can effectively hog the memory system and deny service to benign applications by causing many RowHammer-preventive actions.
We plan to tackle the performance overheads of RowHammer solutions by tracking and throttling the generators of memory accesses that trigger RowHammer solutions. To this end, we propose a research plan to investigate novel methods of identifying threads that reduce memory throughput, and new mechanisms to reduce the negative effects of such threads on system performance and data availability. We hope and expect that our novel techniques and new mechanisms will significantly reduce the number of RowHammer-preventive actions performed, thereby improving 1) system performance and DRAM energy efficiency, and 2) reducing the maximum slowdown induced on a benign application.
Key achievements:
- We show that state-of-the-art RowHammer mitigation mechanisms significantly reduce DRAM bandwidth availability.
- We introduce the idea that it is possible to (1) mount memory performance attacks by exploiting the RowHammer-preventive actions of RowHammer mitigation mechanisms and (2) reduce the performance overheads of RowHammer mitigation mechanisms by observing the time-consuming RowHammer-preventive actions and throttling the threads that trigger such actions.
- We propose BreakHammer, a memory controller-based low-cost mechanism that provides both memory controller-based and on-DRAM-die RowHammer mitigation mechanisms with throttling support to 1) reduce their performance and energy overheads and 2) prevent their actions from being exploited to reduce DRAM bandwidth availability.
- We evaluate BreakHammer and show that it significantly reduces the performance overhead of eight state-of-the-art RowHammer mitigation mechanisms without compromising robustness at near-zero area overhead